



 表計算で「令和」に対応する方法
表計算で「令和」に対応する方法 表計算ソフトで予定表を自動作成する超便利な方法
«How to make the schedule table automatically on
spread-sheet.»
表計算ソフトで予定表を自動作成する超便利な方法
«How to make the schedule table automatically on
spread-sheet.» 表計算ソフトに「個人情報保護機能」を仕込む方法
«Prevention to leak private-data with spread-sheet macro function.»
表計算ソフトに「個人情報保護機能」を仕込む方法
«Prevention to leak private-data with spread-sheet macro function.» Wary-Basher (ワリバッシャー)
Wary-Basher (ワリバッシャー) 貧乏人を殺す行政の構造
«Structurally, the administrators kill the poors in Japan.»
貧乏人を殺す行政の構造
«Structurally, the administrators kill the poors in Japan.»
「準プレーンテキスト」とは,ブラウザ(ウェブ記事閲覧ソフト)でプレーンテキストを表示する時に起こる「文字化け」を回避する対策。
ウェブ記事の規格である HTML では,ブラウザの違いでレイアウトが崩れたり,それを「音読ソフト」に読ませると読む順番が狂ったりすることがあって,そうなると内容を正確に伝えることが困難になる。これは,「避難情報」などの緊急性の高い配信では大きな問題。その点では「プレーンテキスト形式」のほうが,作成も容易で,ほぼ記載順の通り表示する点で適しているが,文字化けし易く,ブラウザによっては全く読めなくなる難点がある。ここでは,HTML を知らなくても記事作成が容易でレイアウトも崩れにくいプレーンテキストの特徴を活かし,HTML
の機能を少しだけ付加して,文字化けなく公開できる工夫を紹介する。
なお「準プレーンテキスト」の呼称は,筆者が勝手に付けたもの。
● 有用性
「準プレーンテキスト」とは,HTML とプレーンテキストの,いわば「いいとこ取り」。特徴は以下の通り。
- 書面の作成が容易。HTML を知らなくても,レイアウトは空白と改行だけで作れるため,「メモ帳」レベルのソフトで作成可能。
- 「サポートブラウザ」に関係なく,日本語対応ブラウザならどれもほぼ同じ書面が読める。レイアウトがブラウザに依存しない。
- 正しく文字コード指定すれば,「文字化け」することなく確実に表示する。
- 他記事への「リンク」なども含ませることが可能。
上記特徴から,さらに以下のような利点が導かれる。
- 正確に閲覧できる可能性が高いため,「避難情報」など正確さが必要な告知で使えば,避難への誘導が円滑になる可能性がある。
- ウェブ記事の規格 HTML を詳しく知らなくてもある程度レイアウトの整った記事が作れるため,緊急時などで人材の確保ができない時でも,とりあえず公開用の文書を作成することができる。
- プレーンテキストと同様,音読ソフトでは,記載した順番通りに読むため,視覚障害者の耳にも記載した内容がそのまま届く。
HTML,プレーンテキストとの比較を表にすると,以下の通り。
▼ 各形式ごとの優位性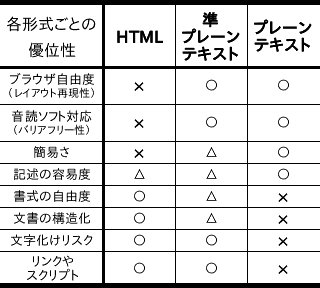 |
◆ 背景……一部ブラウザの劣化
ウェブ記事の標準規格である HTML は,本文の文字以外にも,画像の挿入や文字の色,大きさの指定,複雑なレイアウトも実現できるようになっているが,全てのブラウザで必ずしも同じレイアウトで見れるとは限らない。ブラウザによっては,時としてどこに何が記載されているのか分からないレベルに乱れる可能性もある。また,それを視覚障害者が使うような「音読ソフト」で聞こうとすると,画像や文字の色,大きさなどには意味がないし,むしろ複雑なレイアウトが原因で,読む順番が聞きたい順番と合わなくなることも起こりそうで,そうなると聞いてて理解しにくくなってしまう気がする。しかも,HTML という規格は元々英文向けのもので,通常は空白や改行がいくつ続いていても,「1つの単語の境界」と見なされて,空白1個で置き替えられて1行に入りきるまで前行に詰められる……という英文の記述方式に沿った扱いになる。つまり,段落の意味で入れた改行も,引用を示したつもりの行頭の空白も,読む側のブラウザ(ウェブ記事閲覧ソフト)の表示には反映されない。整ったレイアウトの書面を作りたいと思ったら,ウェブ記事で使われる HTML という記述法をある程度知っている必要があるが,使いこなせる人はそう多くない。ウェブで公開できる文書を作れる人材が限られることになり,緊急時の避難情報のような「迅速に公開したい文書」を作りたい時に困難が生じる可能性がある。
その点「プレーンテキスト形式」は,画像や複雑なレイアウトの指定はできないものの,文書を作った側で入れた「空白や改行」はそのまま表示されるため,それらを使用したレイアウトは HTML を知らなくても比較的容易に作れる。しかも,異なるブラウザでも空白の扱いに違いが少なくレイアウトが崩れにくい。また「本文の文字だけ」のデータのため,「音読ソフト」でも記述された文が順番通り読まれるだけだから,聞く時にも都合がいい場合が多いと思われる。一方,プレーンテキストには内部に「文字コード」を明記する規定がなく,ブラウザで見た時,自動検出した文字コードが違ってしまい「文字化けを起こし易い」という欠点がある。
とはいえ,少し前なら,ブラウザに文字コードを指定して読む機能があったので,いくつか文字コードを試せばたいてい読めていたが,最近はその機能が元からは備わっていないブラウザも多いらしい。すると,そのままでは「文字コード」が設定できないから「文字化けしたら全く読めない」ことになる……粗悪なブラウザが増えただけの気がする。
サーバの設定をいじれない場合は,ウェブ記事を「作成する側で」できる文字化けの防止対策は限られる。「準プレーンテキスト形式」は,その限られた手段の中で最も誰でもできそうなものだと思う。
なお,プレーンテキストで「文字化け」が起きた時に,「読む側で」対策する方法と,サーバ設定での対策については,以下の記事を参照。
● 実際の方法
「プレーンテキスト」には,内部に「文字コード」を示す規定がないが,ウェブ記事で一般的な規格である HTML にはある。だから,「文字コード」を明示した HTML の中に「プレーンテキスト」記事を記述すれば,「文字化け」は回避できることになる。原理としてはそんな感じ。
たとえば UTF-8 という文字コードで記述したテキストを正しく表示させたい時は,以下のようにする。
<HTML><HEAD><META CHARSET="UTF-8" />
<META HTTP-EQUIV="content-type"
CONTENT="text/html; charset=UTF-8" />
<TITLE>表題(この行は省略可能)</TITLE>
</HEAD><BODY><PRE>
:
記事本体(任意の文字データ=プレーンテキスト)
:
</PRE></BODY></HTML>
この“<PRE>……</PRE>”の間の「記事本体」の部分は,空白(スペース)の数も改行の位置もそのままブラウザに表示されるため,空白と改行でレイアウトを作った文書はほぼそのまま見れる。上の5行と最下行の1行だけをどこかに保存しておけば,記事を作成する時に,それをコピペして来て,間に「記事本体」を入れるだけで完了する。
「表題」の行は省略可能だが,設置がお勧め。そこに記載した表題はブラウザのタイトルの部分に表示されるほか,ブラウザのブックマーク(お気に入り)機能を使った時にもそのタイトルになり,あとで分かり易い。また,「音読ソフト」などに「タイトルを読む機能」付きのものがあれば,今読んでいる記事が何であるかを把握し易くなる。この行がないと,そのどの機能も使えないが,もし省略するなら,1行まるごと(つまり <TITLE>……</TITLE>)削除する。
なお,もちろん「記事本体」の文字コードと,上部記載の文字コード(UTF-8 の部分)が一致しないと,結局文字化けしてしまうので注意。作成した文書の文字コード指定は,たいていは「名前付け保存(=いちばん最初の保存)」する時に指定する必要がある。ちなみに,現在世界的に「標準」として使われている文字コードは「UTF-8」と思われる。
また,基本的に HTML 規格なので,例のように「表題」をつけたり,「記事本体」の中に,強調やリンクを付けることも可能。ただし次節の「エンティティ」に注意。
◆ 注意点……エンティティ
注意すべきは,HTML の機能を利用するために,HTML で特殊な意味を持つ文字は,そのまま記述できない点。具体的には,いずれも半角で,不等号(< と >)は,HTML で「タグ」と呼ばれる「書式指定」に使われていて,また & の記号は「エンティティ」と呼ばれる記述法で特殊文字を表すのに使われている。そのため,「記事本体」中にこれらがあると,正確に表示されない。回避するためには,その「エンティティ」と呼ばれる方式を使い,以下のように記述する。
- < → <
- > → >
- & → &
なお,「エンティティ」が関係するのはあくまで半角文字で,全角の文字にはこの心配はない。表記のアルファベットも半角を使う。
逆に「エンティティ」を文中に記載することで,これら以外の特殊な文字の使用も可能になる。たとえば ♥ と書けば ♥
が表示される。
◆ 記事作成に使うソフト
「プレーンテキスト」というのは,文字の装飾(大きさや色を変えたり,斜体や太字にしたり)などが一切無い形式なので,作成に使うソフトは「メモ帳」的な簡易な記述ソフトで十分。一般的に「エディタ」と呼ばれるコンピュータ用のプログラム作成時に使われるソフトが最適だと思う。
「ワープロ」ソフトでも作れなくはないが,保存する時に「プレーンテキスト」で保存することを忘れてしまうと,うまくいかない。また,文字装飾は関係ないため,その機能がサポートされたワープロソフトで作るのは少々重いかもしれない。しかも,それでつい「文字装飾」をしてしまうと,プレーンテキストで保存できなくなる可能性もあるから,注意が必要。それと,この <PRE> で囲む方式では,ブラウザでは「固定ピッチ」のフォントで表示されることが多いから,ワープロで多く使われるプロポーショナルのフォントで作った記事は,レイアウトの再現性はあまりよくない。作成時,最初に「固定ピッチ」のフォントを設定して作成したほうがいいと思われる。
ちなみに,ほぼ同じ名前の日本語のフォントがあり,P の文字が付いているかいないか程度の違いだった場合,付いているほうは「プロポーショナル」で,無いほうは「固定ピッチ」であることが多い。
◆ レイアウト作成上の注意
レイアウトが「崩れにくい」とはいうものの,使えるのは空白と改行だけという制約がある。ただこの <PRE> を使うと,表示に使われるのはたいてい「固定ピッチ」のフォントで,多くは「半角と全角」の幅の比がちょうど 1:2 になっている。それを利用してレイアウトを作れば,ほぼ同じレイアウトを見れることが多いだろうと思う。
が,ブラウザというのは,見る側が必ずしも同じフォントで見るとは限らない。微妙に文字幅が異なれば,「表」のようなものでは右の欄ほど位置がズレていってしまう可能性が高くなる。この方法でレイアウトを作る際は,空行をあけたり,あるいはせいぜい「左側の文字開始位置(インデント)を揃える」のに空白が使える程度と考えておいたほうがいいと思う。
ちなみに,「数字」の文字幅はたいてい各フォントごとに(プロポーショナルでも)同じであることが多い。
◆ SSI が使えれば超簡単
サーバで「SSI」という機能が使えれば,かなり簡単に実現できる。例にあげた「記事本体」以外の部分を別のファイルにしておいて「インクルード」すれば済むことになる。
ただし,この方法では「表題」が付けられないので注意。「表題」はあったほうがいいので,なるべく「記事本体」の前の部分も個々に記載して,「表題」を入れることを推奨したい。
もしやるとすれば,具体的には,まず「記事本体」より上の部分を,たとえば header.html というファイルにする。
<HTML><HEAD><META CHARSET="UTF-8" />
<META HTTP-EQUIV="content-type"
CONTENT="text/html; charset=UTF-8" />
</HEAD><BODY><PRE>
サーバソフトが Apache なら,同じ場所(フォルダ)に記事ファイルを置く場合は,プレーンテキストの記事本体に,以下の最初と最後の行(つまり2行だけ)を付け足せば済むことになる。
<!--#include virtual="header.html" -->
:
記事本体(任意の文字データ=プレーンテキスト)
:
</PRE></BODY></HTML>
なお,SSI の機能を使いたい場合,Apache の Include 機能が有効である必要がある(Apache の Options Includes,または XBitHack ディレクティブを参照)。実際に利用可能かどうかは,サーバ管理者に確認か相談が必要。また,場合により,記事ファイル名の末尾(拡張子)を .html ではなく .shtml にする必要がある。
この方法の利点は,header.html に当たるファイルに,そのサイトの標準ヘッダ(見出しの装飾,トップのロゴやイラストなど)を収録しておけば,サイトのページデザインの統一性を保ちながら,簡単に記事が追加していける点。最下行についても,サイトの標準フッタのファイル(たとえば footer.html)を作成して署名や連絡先を記載しておいて,インクルードで対応させることもできるだろう。
◆ SSI で「タイトル」も入れる方法
この節は,Apache の SSI をちょっと詳しく知っている人向け。
ひょっとすると「内部変数で『表題』を指定できるのでは?」と思っている人もいるかもしれない。筆者も試してみたので,備忘録的に記載しておきたい。
具体的には,まず「ヘッダ」のほうは,こんな感じ。表題を示す変数を title としているが,#if はその指定が無かった場合の対応。
<HTML><HEAD><META CHARSET="UTF-8" />
<META HTTP-EQUIV="content-type"
CONTENT="text/html; charset=UTF-8" /><!--#if
expr="\"$title\" != \"\"" -->
<TITLE><!--#echo encoding="none" var="title"
--></TITLE><!--#endif -->
</HEAD><BODY><PRE>
「呼び出す」本体側は,その「表題」を指定しておいて呼び出す必要がある。だから,include の前に title の指定が必要。
<!--#set var="title" value="タイトル文字列"
--><!--#include virtual="header.html" -->
:
記事本体(任意の文字データ=プレーンテキスト)
:
</PRE></BODY></HTML>
いちおう日本語(UTF-8)を記載しても使えたが,どんな環境下でも可能かどうかは分からない。7ビット文字(最上位ビット7が0)でも使えるかどうか試してみたが,多少複雑だった。というのは,エンティティ(&……;)を使うと,& が & に直されて渡されるようで,しかも ASCII 文字以外は文字化けが起きた。何とか成功したのは,以下のようにして渡した場合(表題は「タイトル」)。
<!--#set var="title" value="&#12479;&#12452;&#12488;&#12523;"
--><!--#include virtual="header.html" -->
HTML なんだから,エンティティをそのまま渡してくれりゃいいのにと思ったが,こうしないとダメだった。まぁ,直接 UTF-8 を記載して機能してくれたら,それに越したことはないと思う。
なお,試した Apache のバージョンが少々古い(1.3)。バージョンにより差が出るのかどうかは分からない。
● じつは HTML の特徴を殺す禁断の方法
じつはこの「全体を“<PRE>……</PRE>”で囲む」という書式の指定は,筆者にとって「最もやってはいけない」と考えていた禁断の方法。そりゃあ,作成者の意図で入れた空白やスペースでレイアウトを作っても,HTML では通常無視されてしまうから,無視されないようにできる方法が使えれば,作成者はそのほうが都合がいいだろうが……。
一方,HTML という規格は,そうした文書に共通する「構造」を示すためにあるような側面があり,そのための符号が多数決められている。たとえば,そこが「見出し」とか「引用部分」とか「箇条書きの項目」であることを示す細かな「きまり」がある。公開された時,つまり外部から読まれる時も,どこが見出しで,引用で,箇条書き項目かといった「文書構造」が,世界共通で分かるように作られている。だから本来,HTML で書かれたウェブ記事は,そうした「構造」をレイアウトに反映するよう作られるべきで,実際,細かい書式の指定をせずに HTML で記述した記事は,自動的にそれなりのレイアウトになる。
つまり,なぜ「禁断」なのかというと,空白と改行だけでレイアウトを作成して「全体を“<PRE>……</PRE>”で囲む」ことは,その「構造を示す」という HTML の特徴を殺すことにほかならないからだ。作成者の意図で空白や改行が入れられてレイアウトが作られると,そこに空白や改行がある理由は,作成者にしか分からない。独自のレイアウトでも,所属する組織内だけで通用すれば済むならいいが,外部に公開する文章でそれをすると,構造が分からないため通用しない状況が起きてしまう可能性がある。
たとえば,いまや「ワープロソフト」は世界共通で使われているが,たいてい「見出しの一覧(つまり『もくじ』)を自動生成する」という機能がある。作成者が「前後に空行が2行ずつあるのが『見出し』」と決めていても,それをコンピュータに伝える方法がないと,コンピュータはどこが「見出し」なのか判断できないから,そうした「もくじ」の自動生成機能が使えないことになる。一方 HTML なら「見出し」を示す記述が決められているため,その「自動処理」ができる。実際,筆者は「もくじ」を付けたい文書は HTML をワープロに取り込んで作ることも多い。「見出し」とそのページ番号の一覧は,ほんの数秒でできる。
「そんなの,どこが『見出し』かくらいは見りゃ分かるだろ」と言いたくなる人もいそうだが,コンピュータは見て判断するわけではない。「世界共通で」使われるワープロだから,「世界共通で」使われている
HTML 文書に合わせて作られるのは,ある意味当然だ。
だから,筆者は今でも,空白や改行を使ってレイアウトを作るのは,「本来的に」禁断だと思っている。
ただ今回は,「プレーンテキストで文字コード指定できず,文字化けして読めない」ような,欠陥品のブラウザが多く出回ってしまったという事情もある。「プレーンテキスト」なら,どんなブラウザでも表示に差がなく,「音読ソフト」などでも正確に情報が伝えられると思われるが,そうした情報提供を妨げる,バリアフリーに逆行するようなブラウザが多く使われるようになってしまったわけだ。「避難情報」のような緊急性のある情報などは,発信する側は「迅速,かつ確実に読めるよう公開したい」と考えていてしかるべきだろうが,やれ「ブラウザを限定しないと正しく見れない」とか,「HTML が分かる人がいないと記事が作れない」などの制限があると,避難が遅れて死に至る人が出てしまう可能性もある。そうした危険性を減らす手段として,「プレーンテキスト」並に容易に作れて,どんなブラウザでも確実に読める「準プレーンテキスト」が役立ちそうな気もしたので,提案する次第。
◆ 遅れている気がする日本の文書処理自動化
HTML のような「文書を構造化する」記述法は「マークアップ言語」と呼ばれることがあるが(末尾の“ML”というのはその意味),それにしても,そうしたものの活用で使えるようになる「目次の自動生成」のような機能を「メリット」と感じたり,逆にその機能が使えないことを「デメリット」として捉える傾向は,特に「日本では」少数派なような気がする。というのは,ネットで配布されていて,ワープロソフトなどで作られたと思われる PDF を見ていると,「ブックマーク」の機能が使われていないことが多いように思われるため。この機能が使えると,読んでいる本文の隣に「目次」を表示しておき,そこの読みたい見出しをクリックすればパッと該当の部分が表示されるから,目次を見ながら「××についてはどう書いてあったっけ」などと,本文の側を行ったり来たりしながら読める,スゴく便利な機能。ただこの機能も,ワープロで「ここが『見出し』」といった「構造」をキチンと示した文書を作らなければ働かない。特に日本語の文書では,その機能が使われていないものが多いような気がする。つまり,まだまだ「構造」を意識した文書の作り方をされることが少ないのだろうと思う。
「構造化がなんぼのもんや?」と思っている人もいるかもしれない。
以前,治療中の患者の病状について,人工知能に何千万件かの論文を読ませて,非常にまれなケースであると特定ができたために治療に活かせたような話を聞いたことがある。それだって,読ませる文書のどこが「見出し」で,「箇条書きの項目」なのか……といった「文書構造」も含めて,コンピュータで内容が把握できるようになっていたからこそできたのではないかと思う。どーせ,その「読ませた」という文書の多くが,HTML などのマークアップ言語で記述された「英文」だったんじゃないか。とすれば,つまり研究成果を文書にしても,「構造化」されていなかったら,そうした「命を救う」ことに役立てられないかもしれない。日本語の文書は,どれほど「世界規模で」活かされるだろうか。
PDF の「ブックマーク」のような機能があまり活かされていない現状を見るにつけ,文書処理にとどまらず,自動化やら効率化やらが,他の国と比較してかなり遅れていると言われている原因の一端を垣間見ているような気もする。
紹介した「全体を“<PRE>……</PRE>”で囲む」方法で記載することは,述べたように,「文書の構造」を示すことを無視するようなもの。構造が明確にされない文書が,前述の「人工知能」や,「検索」の結果などに十分に活かせるとは思えない。つまり,作った文書が活かされない……そうした意味でも「禁断の方法」だと思っている。
● 封印された方法
ちなみに,封印された記述法として,<PLAINTEXT> というのもある。HTML の中にこの記述があると,それ以降は全て「プレーンテキスト」扱いになって,空白も改行も記号もそのまま表示される。ただ,今も,今後についても,ブラウザでの有効性や動作は保証できない。
前述した <PRE>……</PRE> は,中の HTML 表記は有効で,タグによるリンクや文字の装飾もできるが,<PLAINTEXT> では,タグもエンティティも認識しないらしく,不等号(< と >)や & 記号でも,記述したものがそのまま表示されるようだ。
本来なら <PLAINTEXT>……</PLAINTEXT> で囲んだ部分を「プレーンテキスト」として扱う仕様であってよさそうなものだが,述べたように,不等号もそのまま表示するようになるため,エンドタグ(</PLAINTEXT>)も認識しなくなり,ファイルの終わりまで全て「プレーンテキスト」として扱ってしまうことになるのだろうと思う。
リンクを付けたり文字の装飾などもできず,利用価値があまりないと感じられたのか,現規格では「廃止」扱いにされたようだ。